.svg)


June 14, 2025
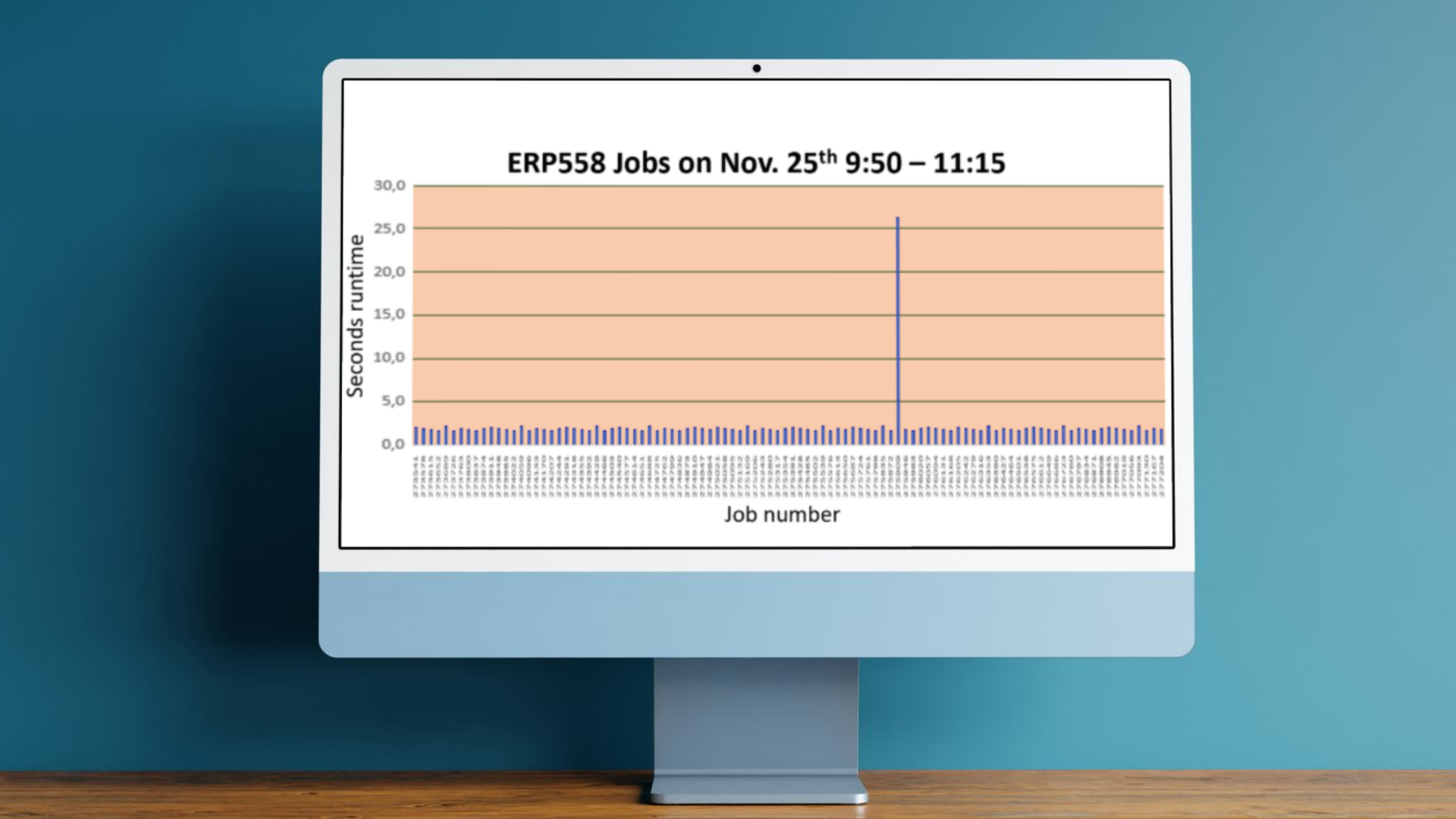
Why FIFO isn’t Always FIFO: Lessons from User Queues on Power i
This is some text inside of a div block.






.svg)










.svg)


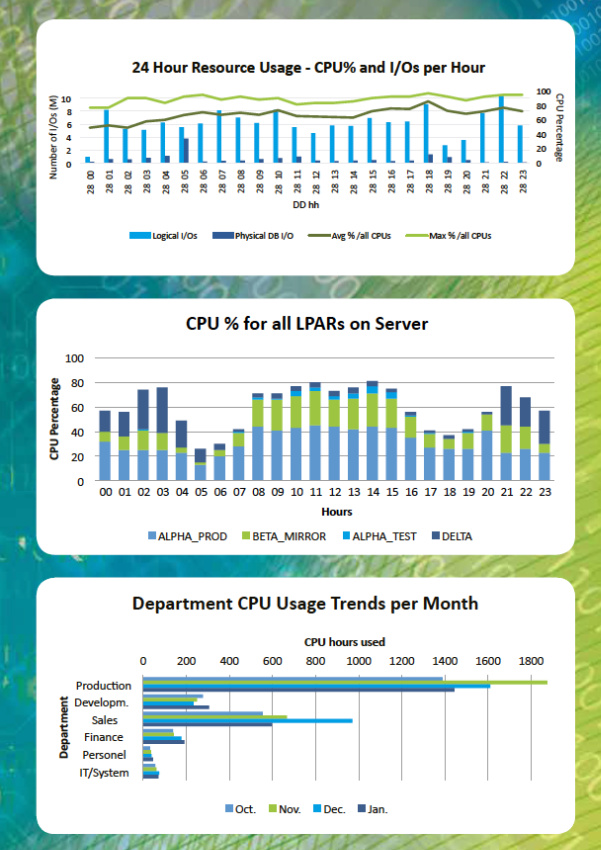
Turning complex performance data into clear insights.
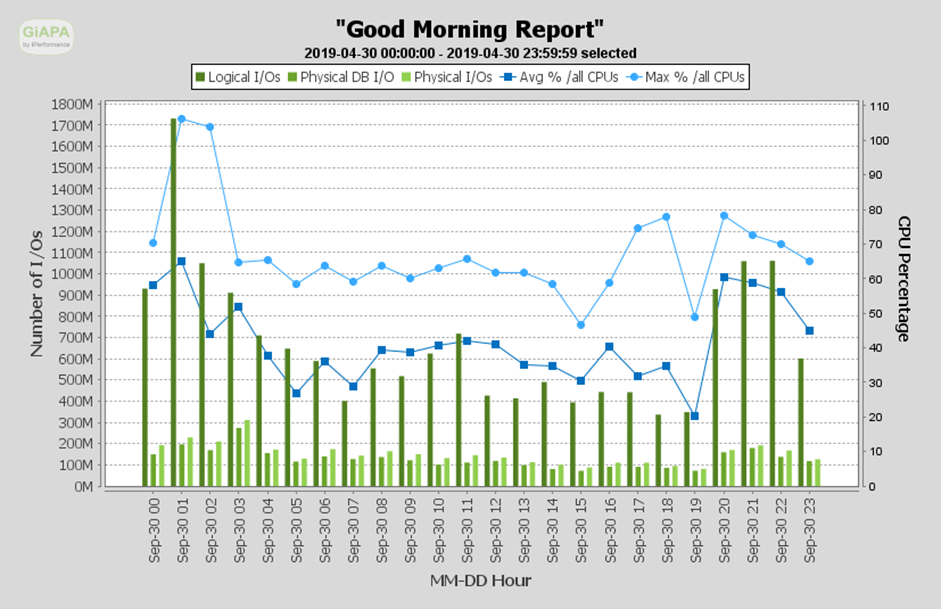
See for all jobs how much and which resources were used.
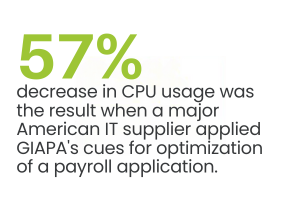
For CPU hogs, additional data documenting the actual activity is collected.
This allows pinpointing optimization potential down to source code line number.
.svg)




.svg)
.svg)


.svg)



.png)
.svg)

In this section, you'll find in-depth articles, practical tips, and real-world experiences aimed at helping system administrators and IT decision-makers improve performance, reduce resource usage, and get more value from their IBM i environments. Whether you're exploring general best practices or diving into specific GiAPA capabilities, our insights are here to guide you. Explore, learn, and optimize.
.png)